
The so-called lossless compression format, as the name suggests, is an audio format that compresses sound signals without loss. Common formats such as MP3 and WMA are lossy compression formats. Compared to WAV files as sources, they have a considerable degree of signal loss, which is the root cause of their 10% compression ratio. The lossless compression format is like compressing the audio signal with a compression software such as Zip or RAR, and the resulting compression format is restored to a WAV file, which is exactly the same as the WAV file as the source! However, if you use Zip or RAR to compress WAV files, you must unzip the zip file before playing. The lossless compression format can be played directly in real time through the playback software, which is exactly the same as the lossy format such as MP3. In summary, the lossless compression format is a format that reduces the volume of WAV files without sacrificing any audio signals.
Commonly used lossless compression algorithms include Shannon-Fano encoding, Huffman encoding, run-length encoding, LZW (Lempel-Ziv-Welch) encoding, and arithmetic encoding.
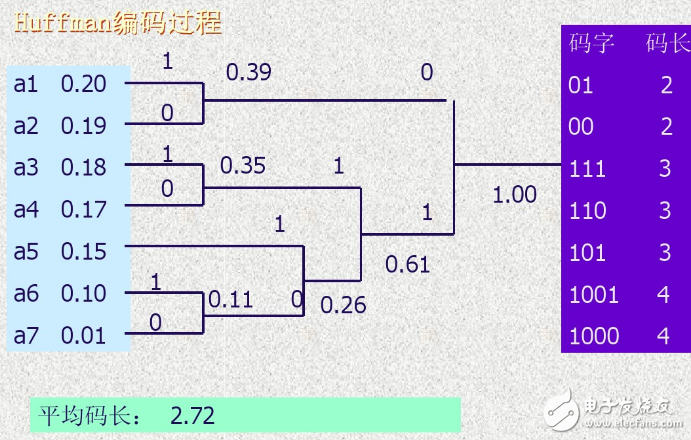
Huffman codingThe method constructs the codeword with the shortest average length of the heterogram head according to the probability of occurrence of the character, which is sometimes called the optimal encoding, and is generally called Huffman coding. It is a coding method in which statistical independent sources can achieve a minimum average code length. The coding efficiency is high.
Fundamental:
The code is constructed according to the probability of occurrence of the source character, the shorter code length is given to the source character with higher probability of occurrence, and the longer code length is given for the source character with less occurrence probability, and finally the coded The average codeword is the shortest.
Coding steps:
(1) Initialization, the symbols are sorted in descending order according to the size of the symbol probability.
(2) Combine the two symbols with the smallest probability into one node.
(3) Repeat step 2.
(4) From the root node to the "leaf" corresponding to each symbol, from top to bottom, "0" (upper branch) or "1" (lower branch) as to which one is "1" and which is "0" is irrelevant. Crucially, the final result is simply that the assigned code is different, and the average length of the code is the same.
(5) Write the code of each symbol from the root node along the branch to each leaf.
Huffman coding points of attention:
Huffman coding has no error protection function. If there is an error in the code, it may cause a series of decoding errors.
Huffman encoding is variable length encoding, so it is difficult to find or call the contents of the file at will.
Huffman relies on the statistical properties of the source. Each codeword encoded by Huffman is an integer: so the average code length is actually difficult to achieve the information entropy.
Huffman codec must have a code table. If the number of messages is large, the code table to be stored is also large, which will affect the system's storage capacity and coding and decoding speed.
Arithmetic coding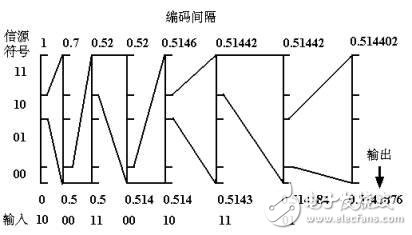
Arithmetic coding represents a set of sources as an interval between 0 and 1 on a real line. Every element in this collection is used to shorten this interval. The more elements of the source set, the smaller the resulting interval. When the interval becomes smaller, more digits are needed to represent the interval. This is the principle of the interval as a code. Arithmetic coding first assumes a probability model of a source and then uses these probabilities to narrow the interval representing the source set.
Arithmetic coding uses two basic parameters:
The probability of a symbol and its coding interval
The probability of the source symbol determines the efficiency of the compression coding, and also determines the spacing of the source symbols during the encoding process, and these intervals are comprised between 0 and 1.
Several issues to be aware of in arithmetic coding:
1. Since the accuracy of the actual computer cannot be infinitely long, overflow in the operation is an obvious problem, but most machines have 16-bit, 32-bit or 64-bit precision, so this problem can be solved using the scaling method.
2. The arithmetic coder generates only one codeword for the entire message. This codeword is a real number in the interval [0, 1), so the decoder cannot decode until all bits representing the real number are accepted.
3. Arithmetic coding is also an encoding method that is sensitive to errors. If one of the errors occurs, the entire message will be translated.
Run-length encodingRLE (Run - Length Encoding) is a compression scheme for data containing multiple iterations in a sequence. The principle is to replace a series of repeated values ​​with a single value plus a count value, which is the number of consecutive and repeated units. If you want to get the raw data, just expand the code.
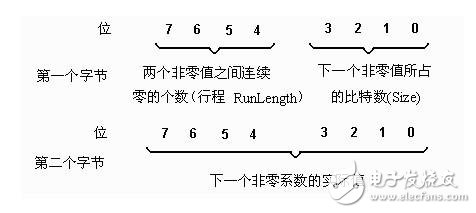
Comparing the number of codes before and after RLE encoding, it can be found that 73 codes are used to represent the data of this line before encoding, and only 10 codes are used to represent the original 73 codes after encoding. The ratio of data before and after compression is about 771. , that is, the compression ratio is 7:1. This shows that RLE is indeed a compression technology, and the coding technology is practical.
The performance of RLE depends mainly on the characteristics of the image itself. RLE compression coding is especially useful for computer-generated images and is very effective in reducing the storage space of image files. However, since natural images with rich colors have fewer consecutive pixels of the same color on the same line, fewer consecutive lines have the same number of consecutive lines. If the RLE encoding method is still used, not only the image cannot be compressed. The data may instead make the original image data larger.
The decoding is performed according to the same rules as those used in encoding, and the data obtained after the restoration is exactly the same as the data before compression.
Therefore, RLE is a lossless compression technique that is used in encodings such as BMP, JPEG/MPEG, TIFF, and PDF, and is also used in fax machines.
LZW encoding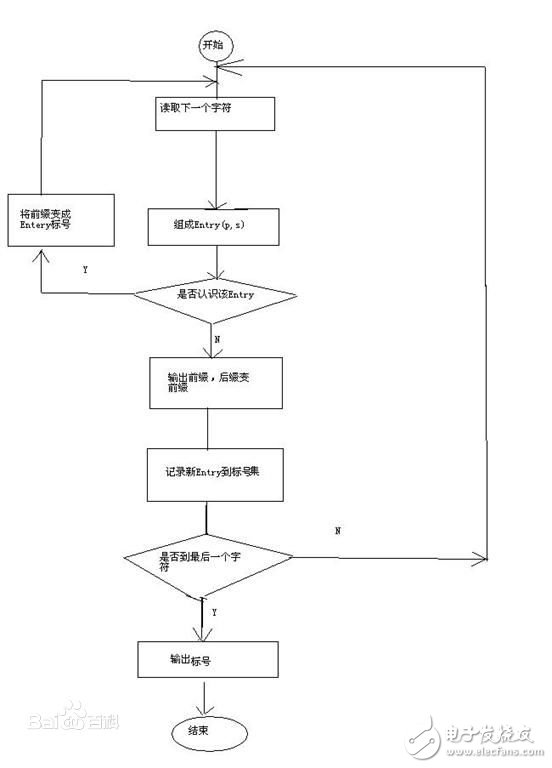
LZW implements compression by creating a string table that uses shorter code to represent longer strings. The correspondence between string and encoding is dynamically generated during the compression process, and is implicit in the compressed data. When decompressing, it is restored according to the table. It is a lossless compression, the full name of Lempel-ziy- Welch encoding, referred to as LZW. Compression algorithm.
Fundamental
Extract the different characters in the original text file data, create a compilation table based on these characters, and then replace the corresponding characters in the original text file data with the index of the characters in the compiled table, reducing the original data size. It seems to be similar to the implementation of the palette image, but it should be noted that the compiled table here is not created in advance, but is dynamically created from the original file data, and the encoded data is also decoded. Restore the original compiled table.
The specific steps of the LZW encoding algorithm are as follows:
1. The dictionary at the beginning contains all possible roots, and the current prefix P is empty;
2. The current character (C): = the next character in the character stream;
3. Judging the level - whether the string P+C is in the dictionary
(1) If "yes": P:=P+C// (expand P with C)
(2) If "No
1 output the codeword representing the current prefix P to the codeword stream
2 add the suffix-string P+C to the dictionary;
3 Let P:=C/ (now P contains only one child C)
4. Determine if there are still codewords to be translated in the codeword stream.
(1) If "Yes", return to step 2
(2) If "No"
1 output the code representing the current prefix P to the codeword stream
2 ends
Disposable vape pen Onlyrelx 600puffs is portable and fashion disposable electronic cigarette, disposable ecigs pen are trending featured vape pen for vapors as it's safety and easy to use. Disposable vape pod,disposable vape, wholesale vape,vape wholesale,vape pen manufacturer and supplier.disposable vape pen,disposable electronic cigarette,disposable ecigs pen,disposable ecigs stick,disposable e-cigs pen,disposable vape factory,disposable vape pod,disposable vape device,vape pen,vape stick, vape wholesale,wholesale vape,customized dispsoable vape pen,customized vape pen,OEM&ODM disposable ecigs pen,disposable electronic cigarette wholesale, wholesale disposable electronic cigarette,distribute vape pen,vape pen distribute,high quality vape pen,high quality vape pod,rechargeable disposable vape pen,refillable vape pen,refilling electronic cigarette,rechargeable disposable electronic cigarette,refillable vape pod,disposable refillable ecigs,disposable refilling e-cigs pen,refillable e-cigs pen
Onlyrelx Bar600,Onlyrelx flat shape bar,Mini Vaporizer Onlyrelx,Original Onlyrelx Vape Pen,disposable vape pen,disposable vapes pen
Shenzhen Onlyrelx Technology Co.,Ltd , https://www.onlyrelxtech.com