Gai Kun, known as "Jingshi", is a senior director of Alibaba Group's "Precise Responsible Realization" division of Alibaba Group. On March 29th, at the Xinzhiyuan Industry-Transition AI Technology Summit, Gai Kun explained the road of deep learning of Alibaba's mother, the experience and problems of using deep learning to recommend advertisements, search the entire library, and so on. Dry goods full, this article brings exciting records.
As the senior director of Alibaba's mother precision display technology department, Gai Kun's flower name in Alibaba is Jing Shi, which has become an “algorithm genius†by the outside world. In 2011, Gai Kun, who had just entered Ali, proposed a fragmented linear model MLR, which was significant for the industry that used the simple linear model for CTR estimation at the time, because it greatly improved the accuracy of CTR estimation. For several years, the MLR model has been widely used in the through-training and drilling business.
Gai Kun led the team to launch a new model structure in CTR forecasting - the deep user network interest distribution network, which suggested that the user's interest is diverse, using deep learning to establish between the user's historic behavior and the advertising CTR prediction. With partial matching, historical data with a higher degree of matching have a greater influence on the prediction result, so as to distinguish current user interest points. At the Xinzhiyuan Industry and Transition AI Technology Summit on March 29, Gai Kun interpreted these algorithms.

Gai Kun: I am very pleased to communicate with everyone on the road of “deep learning and evolutionâ€. Ali’s mother is a big data marketing platform under the Alibaba Group and is a business unit responsible for the realization of Alibaba. I have a flower name in Ali. Everyone inside Ali communicates and contacts with a flower name. My name inside Ali is Jing Shi. The research direction is machine learning, computer vision, recommendation system, and computational advertising. My undergraduate and Ph.D. students at Tsinghua University majored in computer vision. After graduating, I joined the Alibaba Advertising Technology Department and later formed Ali's Mom Division. This division is responsible for all of Ali's advertising cash products. I am now a researcher of Ali Mama. I am responsible for the precise targeting of the advertising technology team. I am responsible for products such as smart drilling exhibitions and direct advertising through trains. Classmates familiar with Ali system may know these two products.
I will talk about it in three parts. First talk about the evolution of deep learning under Internet data, and then talk about how to use deep learning in advertising recommendation or search business, how to solve the problems encountered in the search with deep learning, and finally look forward to the future challenges.

First of all, big data under the Internet. What are the characteristics of Internet data? The first feature is large scale, and the language that translates into machine learning is particularly high-dimensional, with a large number of samples, and there are also rich internal relationships within the Internet data.
Here is an example. For example, this is a typical APP or data on an Internet site. There are many users on one side and many materials on the other side. Taking e-commerce as an example, materials are commodities. We now have a lot of users who have a lot of commodity materials. Both of these are big data. Historically, we will see a lot of behavior. This is a certain kind of connection between users and products. After that, each user has his profile information, the user sees the title of the product, the details page, comments, etc., so that the very large-scale data that is extended will be connected by these relationships. This is the characteristic of Internet data. .
CTR estimate. Taking the classic question as an example, why is CTR estimation important? This is the core technology in the advertising, recommendation, and search business. The importance of these businesses is believed to be no more needed. These three businesses are the core business of many companies. Taking advertising as an example, why is CTR estimation in advertising important? There are two points. First, CTR estimates are fertile ground for deep learning research in the advertising market. There are many new technologies that can be explored and evolved. Second, the CTR estimate is directly related to the Internet company's platform revenue. It is actually more important to AI. We all know that many AI companies now, including the internal research direction of the company, are in fact the layout of the future. Where does the cash flow come from? Many Internet companies come from advertising advertising, so advertising is important.
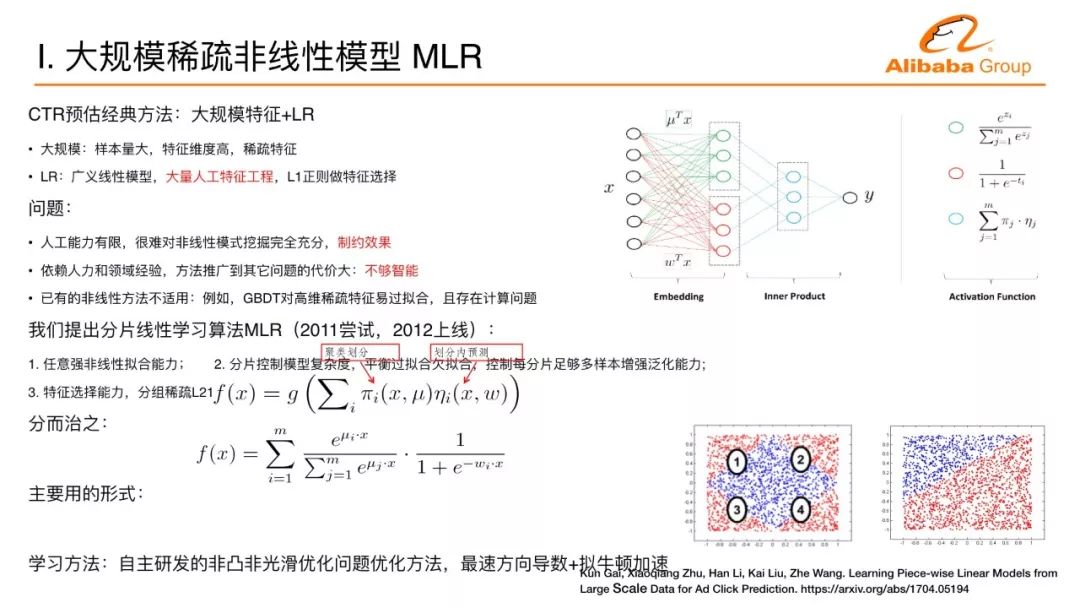
Taking advertising as an example, the application of CTR in the core issues of deep learning CTR is estimated. The traditional methods of CTR estimation are divided into two categories. The first category is the strong features of artificial design, and the dimensions are not very high. In general, some are Strong statistical characteristics, this feature on the traditional approach, the company represented by Yahoo uses the GBDT method. The problem with this approach is that although it is very simple and effective, the manual processing of the data makes the data lose its resolution and the data dimension is very low. The second mainstream approach is to develop data into high-dimensional data. The classic approach uses large-scale logistic regression. Logistic regression is a generalized linear model. The model is very simple, but its model capability is limited.
Before introducing the introduction of deep learning, I first started with my first work on Alimama. We changed the logistic regression from a simple linear model to a nonlinear one, and turned it into a three-layer neural network. As mentioned above, a classic approach uses large-scale data + logistic regression. One problem with this logistic regression is that linearity is too simple. We need to do a lot of artificial feature engineering to make this effect better. Our first thought here is how to make the algorithm more intelligent and automatically extract non-linear patterns in large-scale data.
We made such an attempt to do a piecewise linear model, and the ideas behind it are also more intuitive. The entire space is divided into a number of areas, each of which is a linear model. Different regions make some smooth connections. The entire space is a piecewise linear model. When the number of regions is large enough and the number of shards is sufficient, you can approach any complex nonlinear surface.
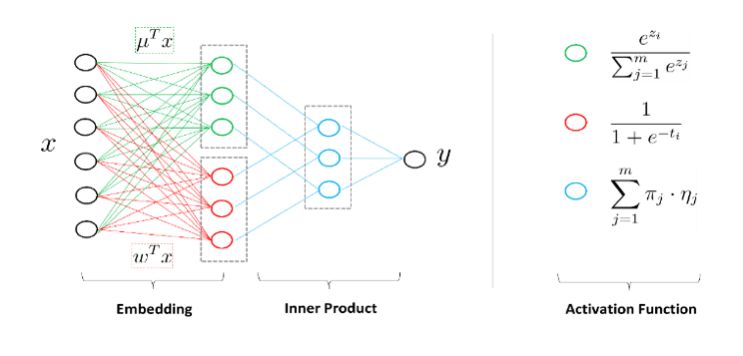
This is a schematic of the model from the point of view of a neural network. How to calculate after coming to a sample? First, the degree of membership for each region is calculated. Assuming that there are four regions, a degree of membership is calculated. Assuming that this sample belongs to the first zone, the degree of membership is 1000, and there is also a predictor or linear classifier in each zone, and there is a prediction value for each zone. These four prediction values ​​constitute another vector. The above four-dimensional vector and the following four-dimensional vector do an inner product. The prediction value of the first region is selected. It is actually a soft membership degree rather than a hard one for mathematics processing.
How to learn this learning model is a major issue. We have also added a technique for grouping coefficients so that models under Big Data have the ability to automatically select features. In the end, it will turn into a non-convex and non-smooth problem, which is the model proposed in 2011 and the algorithm going online in 2012. The problem of non-convex and non-smoothness was not a good method at the time. Non-smooth mathematics did not represent everywhere. It was also a problem that there was no mathematical derivative of the derivative. Although not everywhere, this function can be directed everywhere. We use the directional derivative to find the fastest descent direction and use the quasi-Newton method to accelerate it. The name of this job is called Mixed Logistic Regression (MLR). Students who have done CTR estimation may know such a job. This is a basis for us to explore the application of deep learning in advertising.
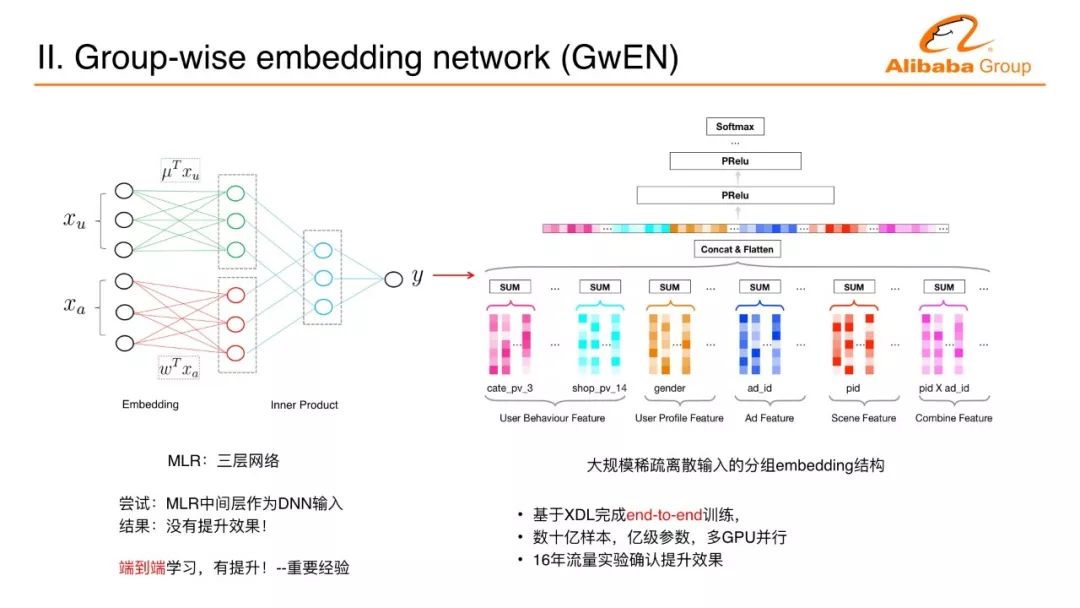
MLR is a three-layer neural network that transforms large-scale, sparsely discretized inputs into two vectors as inner products. The two vectors are spliced ​​together as a long vector, the same as today's embedded technology. By embedding a particularly large amount of data and poorly processed data into a space as a vector, it is very easy to deal with some continuous vectors in continuous space with deep learning such as multi-layer perceptrons. The first step of deep learning is a very important experience. Through all the deep learning design concepts, the middle layer vector generated by the MLR is extracted, and the multi-layer perceptron is directly implemented. The intrusion vector is used as a multilayer. Sensor input. There are two reasons why this does not improve the effect. First, MLR is inherently a nonlinear model; the second point is because there is no end-to-end training.

The latter breakthrough, which combines embedding learning with the training of multi-layer perceptrons to end-to-end learning, has significantly improved over the original technology. This can also explain why deep learning has achieved major breakthroughs and progress in the last decade. If there is no end-to-end training, use the shallow model to generate features for each training and then re-generate the feature layer. Many people have not tried to reach this kind of deep cascading network until the end-to-end learning, which has led us to make breakthroughs on many issues. We put the embedding of the group up and the multi-layer perceptron above. This became the first generation of deep learning network for Ali Mam, based on tens of billions of samples, hundreds of millions of feature dimensions, and multi-GPU end-to-end training. A business goes live. This on-line effect makes the promotion of CTR and GMV very obvious.
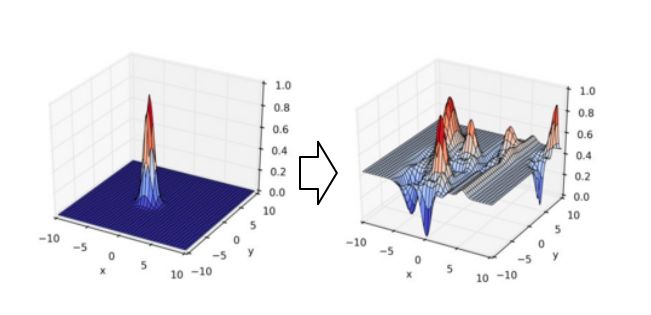
In the foregoing, we introduced the application of classical comparatively standardized deep learning in advertisements. Next, our direction in Internet data, how can we make better deep learning models through insight into user behaviors. Here is an example. We have just talked about embedded technology. Each commodity is represented in the embedding space by embedded technology. A set of characteristics of the user's behavior is expressed as a point through embedded technology, which may represent the user. This user point and the product do the calculation of the final interest, assuming that this calculation is proportional to the distance, the user's point will be expressed as such an interest function will become a unimodal function in space, the user is located The point of interest has the greatest degree of interest, and the farther away the interest is.
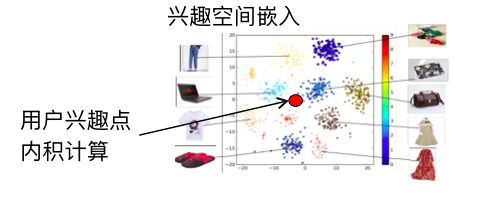
In fact, is the interest of our users a single peak? We don't think so. Did everyone have any shopping experience in Double 11? Whether it is a shopping cart filled with many different types of goods, indicating that the user's interests are diverse, we in the non-active node, usually found that the user's interest is also diverse. The user's behavior sequence contains a large number of different sub-sequences of the category, and the users jump to each other.
Based on this insight, we propose a deep learning neural network with user distribution of multimodal interest. We hope to describe the user's multiple interests. The method it uses is subsequence extraction. When we do a CTR estimate, we have a candidate product. When we get a candidate product to estimate its CTR, use this product to reverse extract it. Helps subsequences, not all sequences. In this case, the relevant subsequence can be extracted in a complex sequence containing many subsequences, and the related subsequences can be used to form an expression and be associated with this product. The distribution of multimodal interest can be regarded as any one commodity to find a more recent peak and calculate the degree of interest, which is probably such a process.
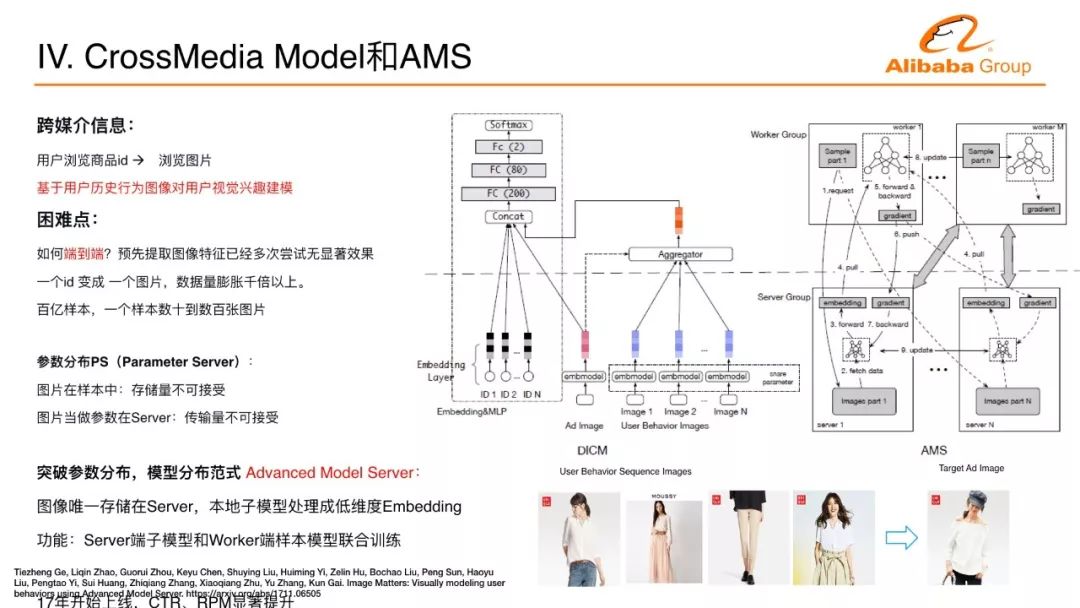
We actually use a technology similar to the attention to achieve the relevant purpose, but also to significantly improve the CTR and GMV's significant indicators in the flow effect of Ali Mama. When users browse various materials on the Internet, the understanding of the nature of the materials behind them is very important. For example, in the e-commerce environment, when users browse the products, they often see the picture of the product to determine how it will proceed to the next step. the behavior of. Can we put these picture information into deep neural network to do better user interest modeling? This poses a challenge. Any one behavior changes from the ID of the product to a picture of a product. The amount of data in the sample is increased by many times. An ID may be represented by a few bytes of bytes. If it becomes a picture, With a few hundred k or even trillions, the amount of data is at least a thousand times faster. The large-scale data on the Internet requires tens or hundreds or thousands of machines to train in parallel. The data volume has exploded several thousand times. Even for companies such as Alibaba, such problems are difficult to deal with.
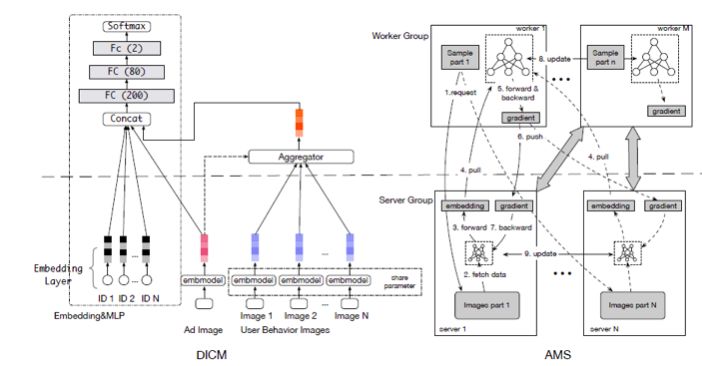
How to solve this kind of challenge? We analyzed the distribution method that is often used in the deep learning modeling of the Internet and called Parameter Server. My sample has a worker that traverses the samples and takes parameters from the server when parameters are needed. Can you afford such calculations? The image was first stored in the sample, and it was unacceptably thousands of times to expand. There exists a remote sever image for de-redundant storage, storage can be resolved, and the associated image is transmitted, and the data volume explosion is thousands of times unacceptable. Remote can not only store the parameter image, the remote is not a model to solve? The remote image has a model, the remote model handles the child model of the image part, and the worker end is the CTR master model that traverses the samples. These two models are grafted together and do an end-to-end training. As I said just now, it is an important experience that only works from end to end. This image feature was attempted by many teams within Ali's mother, adding the image into a feature to the CTR prediction model. If the CTR prediction model is strong, it would have no effect. We do such an end-to-end training, propose a new server for model distribution, and change the parameter distribution method to a model distribution method. The server side has not only parameters but also sub-models are calculated, and will be updated together with the worker-side master model. This allows the image to be processed as a vector retransmission, several tens of times, a few hundred times, and the entire transmission volume is reduced, making the entire joint training process possible. Through the distributed changes in the framework to complete this challenge, Alimama's internal business online, there is a significant increase in the click-through rate or the profitability of the business platform.
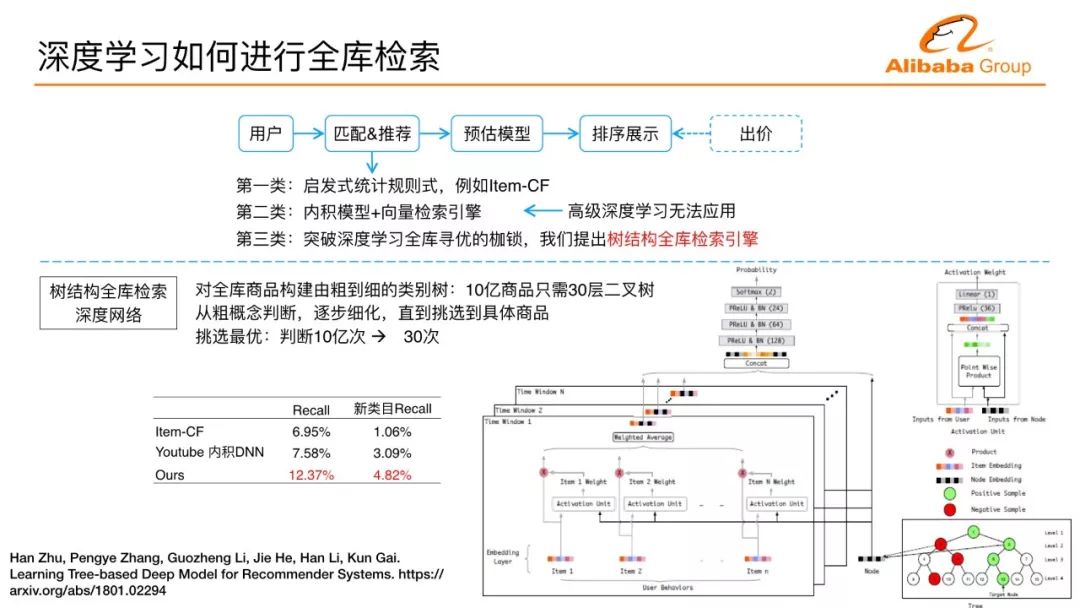
Deep learning is really used in the search system of search ads, and it will encounter matching problems or search problems. Such a traffic-side service is generally divided into several modules. After a traffic flow, a traffic flow usually represents a user's browsing behavior under a certain scenario, first match, and the subsequent estimation model does for a given commodity. Estimates of interest, click-through rate estimates, and conversion estimates. There are some sorts of rankings behind the forecast. There are also bids for ads, and there are no bids for non-advertisements. However, it is not possible to estimate the entire material warehouse.
Assuming that there are 10 billion materials behind each user, it is impossible for each user to calculate the clickthrough rate of 10 billion materials online. The matching module in the front needs to be reduced to a few thousand and ten thousand, making online can bear so much Calculations. The preceding search matching link in the process is the upper limit of the overall system performance. The latter model is in any case more elaborate and the front matching is very weak, and the overall business objective cannot be improved. Matching methods can be divided into three categories. Heuristic statistics rules are now very sophisticated, and it is recommended that a very large number of collaborative filters be used. The two products look similar, and how does collaborative filtering match? By matching the similar products of the baby's merchandise with historical behavior, many people will encounter such a recommendation that is easy to personalize, and will be greatly improved for non-personalized business indicators. To a problem, users often see similar products with historical behavior, which may have some cases in which users complain.
A very natural idea of ​​improving matching ability is to introduce machine learning to measure interest and find the best product. With the introduction of machine learning, the entire library's computational problems are difficult to solve, so we have a degenerative method when introducing machine learning. If the model is an inner product model, the user is a vector point, and all materials can represent vector points. The inner product model eventually becomes a KNN lookup problem. How to find the nearest neighbor? There are vector search engines that can do it. There are often cross features in CTR, distribution of user interests, and many advanced deep learning modes. There is no way to use them here. We aim at optimizing the use of arbitrarily deep learning to search the entire library, and propose a tree-structured full-library search engine. Its idea is also more intuitive, and the entire commodity is built as a hierarchical tree with one billion products. A 30-story binary tree, its leaf layer can accommodate 2 billion commodities. Each layer of our deep learning layer scans, each layer finds the best, the lower node does not continue to calculate in the upper layer of non-optimal children, equivalent to discard, until the last to find the best in the entire library, to 1 billion times The measurement has become a measure of 3 billion top-to-bottom measures, solving the problem of how deep learning can find the best in the whole library, and solves the problem of retrieval and matching. This method compared with the previous two generation methods, the recommended recall rate has a very significant increase. In addition, we restrict the recommendation that users do not act on materials under the category, and use the new category recall rate as a comprehensive assessment of novelty and recall rates. Compared to the first generation of collaborative filtering methods, this approach has nearly quadrupled. This is a technical solution to the problem of how to use deep learning to perform a full library search.

In the future, for the problems of recommendation or advertising experience and missing data, machine learning needs label data, which is the target data, and some of the current goals are the user data that has already been generated and clicks to purchase data. We are able to optimize these metrics. Many of our experience problems are difficult to optimize without Label, making it difficult to use machine learning to solve these problems. How to solve the problem of experience? Use algorithms to automatically derive the user experience behind or use manual tagging, such as search engines using relevance teams to annotate user's feelings or interacting to let users take the initiative to feedback? This is a question that needs to be explored in the future.
The evaluation question is recommended by industry and academia. Efforts are often made to evaluate the recall rate. In fact, the recall rate only evaluates the performance of the users who have consumed the product, and how to evaluate the effect of the newly recommended product on users. This has not been evaluated in the recall rate. reflect. There are also recommended self-circulation issues. If you are interested in something, you will be recommended more and more. Finally, you will lose many other recommendations that may be of interest to you. There are many recommended scenarios on many APPs. How do you collaborate on multiple scenarios? From the perspective of the business, each merchant is actually facing the massive amount of users, how to detect potential customers. Businesses are faced with the entire consumer operation process, how to optimize and innovate on the entire link of the potential interest phase and the purchase phase. This is a problem that the merchants hope to solve in the business.
Ali Mom's technical team continues to evolve and innovate in deep learning. We are pursuing business results and we hope to be able to do something different in technology behind the pursuit of business results. We hope to be able to do some innovative business models. If there are any students interested in us, please contact us. Ali Mother and Tianchi organized the Ali Moms International Advertising Algorithm Competition organized by Tianchi. Everyone was interested to welcome the challenge.
Ali Mama International Advertising Algorithm Competition:
Alibaba (Taobao, Tmall) is China's largest e-commerce platform, providing convenient and high-quality transaction services for hundreds of millions of users, and has accumulated a wealth of transaction data. Alibaba’s mother, Alibaba’s advertising business unit, has used this data in the past few years to use artificial intelligence technologies such as deep learning, online learning, and reinforcement learning to effectively and accurately predict users’ purchase intentions, effectively improving the user’s shopping experience and advertiser’s ROI. However, as a complex ecosystem, factors such as user behavior preference, long tail distribution, and hot events marketing in the e-commerce platform still pose great challenges to the conversion rate estimation. For example, during the Double Eleven shopping carnival, the promotion of businesses and platforms will lead to drastic changes in the distribution of traffic, and models trained on normal traffic will not be able to match these special flows well. How to better use the massive transaction data to predict the user's purchase intention efficiently and accurately is a technical problem that artificial intelligence and big data need to continue to solve in the e-commerce scene.
In 2018, Alibaba mother joined forces with the International Artificial Intelligence Conference (IJCAI-2018) and Alibaba Cloud Tianchi platform to launch the Alibaba Mama International Advertising Algorithm Contest. Using Alibaba E-Commerce Advertising as the research object, it provided a platform of massive real-life scene data. Artificial intelligence technology builds a predictive model that predicts the user's purchase intention. The winning team not only has generous bonuses and travel sponsorship fees, but also has the qualification to attend the IJCAI-2018 Main Conference held in Stockholm in July.
Marine High Temperature Pressure Sensor
Product overview high temperature pressure sensor is a signal measuring element. The measured medium pressure is transmitted to the sensor through the heat dissipation structure on the transmitter. The high-precision signal processing circuit is located in the stainless steel shell to convert the sensor output signal into standard output signal. The whole product has undergone strict testing and aging screening of components, semi-finished products and finished products, with stable and reliable performance, so that the product can work stably for a long time when used for pressure measurement of high-temperature medium. Product features 1. 316L stainless steel isolation diaphragm structure 2. Imported high temperature resistant chip 3. Wide applicable medium temperature range 4. Strong anti-interference and good long-term stability 5. Direct contact with high-temperature medium to improve pressure response frequency 6. Provide rich pressure range of low pressure, medium pressure and high pressure
Marine High Temperature Pressure Sensor,Marine Temperature Pressure Sensor,Pressure Sensor With Led Display,High Temperature Pressure Sensor
Taizhou Jiabo Instrument Technology Co., Ltd. , https://www.taizhoujbcbyq.com